UrbanLoc: Language-Guided User Localization via Location-Aware Multimodal Retrieval
Abstract
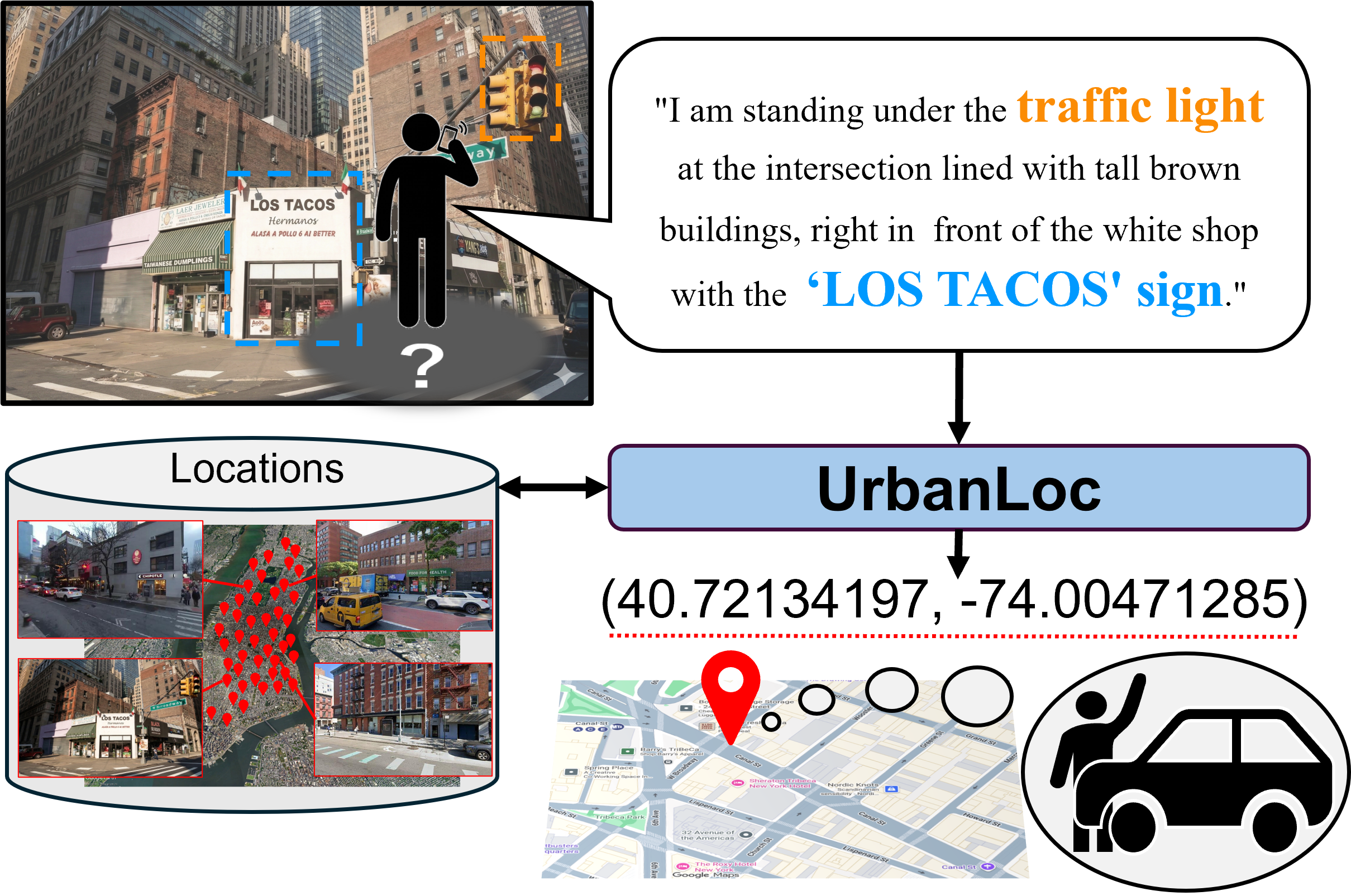
Autonomous personal mobility and on-demand robotic delivery services require estimating user locations in diverse environments in order to dispatch robots to appropriate pickup or drop-off points. Although GNSS-based user localization is widely used for this purpose, it does not always function reliably due to signal degradation in urban canyons or in situations where sensing is restricted. In contrast, language-guided user localization offers a complementary, hardware-agnostic alternative, allowing users to describe their surroundings in natural language under modality-restricted conditions. Such language-guided user localization is challenging because users typically refer only to salient landmarks or text on signs, leading to a many-to-many correspondence between linguistic descriptions and possible locations in large-scale environments. To address this, we propose UrbanLoc, a two-stage language-guided user localization method via multimodal retrieval over geotagged street-view images. Unlike existing approaches, UrbanLoc leverages complex vision-language cues (e.g., storefront signage) that users typically describe in practical large-scale environments. To this end, we introduce location-aware vision-language alignment using area summaries, along with MLLM-based reranking using object coverage. To validate UrbanLoc, we construct the UrbanLoc-Text benchmark consisting of 34k descriptions referring to 15k locations within 200 km² regions. Experimental results show that UrbanLoc outperforms baseline methods on standard evaluation metrics.
Method
UrbanLoc consists of two modules, the Location-Aware Text Module (LATM) and the Multi-Cue Visual Module (MCVM), together with object coverage reranking.
LATM maps an input description to a location-aware text representation. An auxiliary location head is supervised with a great-circle distance loss, encouraging the text representation to reflect geographic proximity.
MCVM captures both visual and location-related cues from each geotagged image through visual appearance features and geographic features. It includes a CoT Narrative Representation, an Area Summary, and Scene Text Normalization.
UrbanLoc reranks candidate locations by computing an object coverage rate — the fraction of objects mentioned in the user's description that are matched in the candidate image's CoT narrative explanation — and adding a weighted coverage term to the retrieval score.
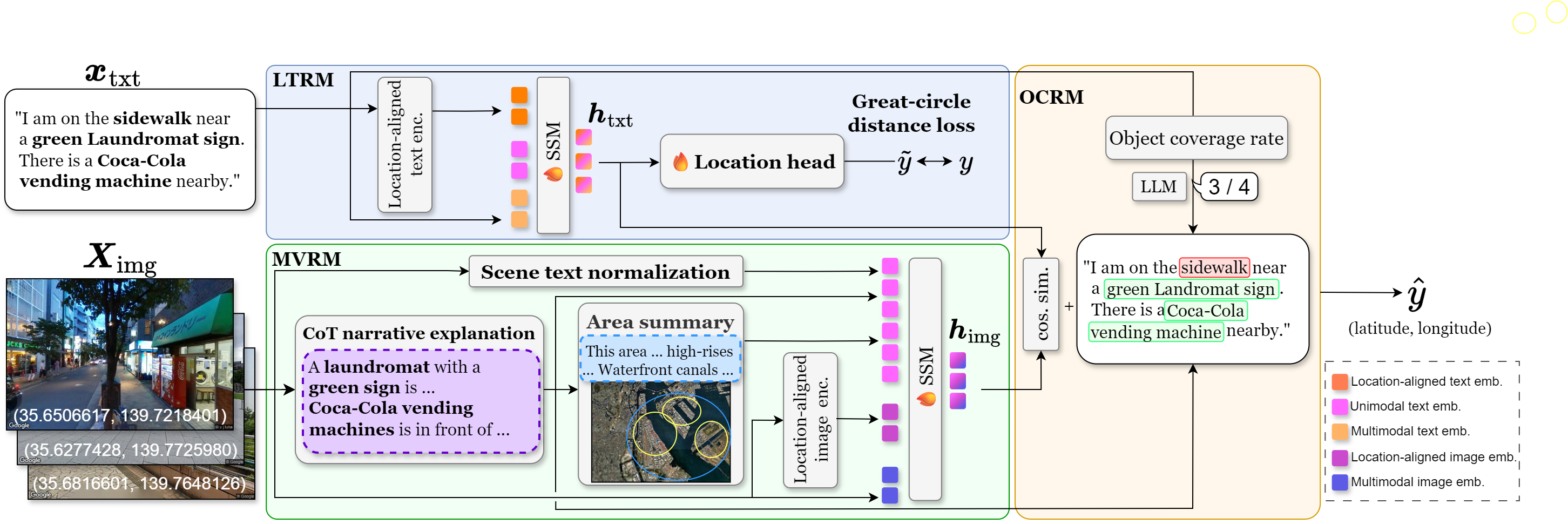
Architecture of UrbanLoc. The model takes a user description and a set of geotagged street-view images. LATM obtains a location-aware text representation, MCVM combines visual appearance and geographic cues, and object coverage reranking promotes candidates that match all specified objects.
Key Contributions
- UrbanLoc: A two-stage language-guided user localization method via multimodal retrieval over geotagged street-view images, leveraging complex vision-language cues (e.g., storefront signage) that users typically describe in practice.
- Location-aware vision-language alignment: An auxiliary location head with great-circle distance supervision integrated into the text encoder, enabling the model to reflect geographic proximity in its representations.
- Area summary: A submodule that captures area-level characteristics shared across nearby locations, mitigating the partial and viewpoint-dependent nature of individual street-view observations.
- Object coverage reranking: A reranking term that promotes candidate locations matching all objects specified in the user's description, addressing the limitation of global cosine similarity scores that may over-rank partially matching candidates.
- UrbanLoc-Text benchmark: A new benchmark consisting of 34k descriptions referring to 15k locations across 200 km² regions in multiple cities (New York and Tokyo).
Quantitative Results
Comparison between UrbanLoc and baseline methods on the New York and Tokyo subsets of the UrbanLoc-Text benchmark. The mean and standard deviation over five trials are reported for fine-tuned models. Best scores are in bold, second-best are underlined.
| Method [%] | FT | New York | Tokyo | ||||
|---|---|---|---|---|---|---|---|
| L@50 ↑ | R@1 ↑ | R@5 ↑ | L@50 ↑ | R@1 ↑ | R@5 ↑ | ||
| CLIP | ❄ | 10.5 | 10.1 | 19.1 | 11.1 | 10.8 | 22.0 |
| CLIP | 🔥 | 18.9 | 18.3 | 31.8 | 19.3 | 18.8 | 34.2 |
| BEiT-3 | ❄ | 14.6 | 14.1 | 29.0 | 14.9 | 14.5 | 31.9 |
| BEiT-3 | 🔥 | 17.5 | 16.6 | 31.6 | 17.8 | 17.3 | 34.7 |
| BLIP-2 | ❄ | 6.4 | 6.2 | 14.1 | 7.7 | 7.2 | 16.8 |
| BLIP-2 | 🔥 | 17.9 | 17.7 | 34.2 | 19.8 | 19.4 | 37.6 |
| SigLIP | ❄ | 16.1 | 15.5 | 28.3 | 16.4 | 16.2 | 30.6 |
| SigLIP | 🔥 | 21.5 | 20.7 | 35.3 | 18.3 | 17.8 | 34.5 |
| Long-CLIP | ❄ | 11.4 | 10.8 | 21.7 | 13.1 | 12.7 | 26.2 |
| Long-CLIP | 🔥 | 17.2 | 16.6 | 30.9 | 18.4 | 17.8 | 34.5 |
| CrossText2Loc | ❄ | 1.2 | 1.0 | 3.1 | 1.1 | 0.9 | 2.6 |
| CrossText2Loc | 🔥 | 2.5 | 2.2 | 5.8 | 3.2 | 2.9 | 4.5 |
| SigLIP 2 | ❄ | 15.1 | 14.9 | 28.4 | 14.5 | 14.2 | 29.6 |
| SigLIP 2 | 🔥 | 19.7 | 18.9 | 34.3 | 22.7 | 22.1 | 40.7 |
| Meta CLIP 2 | ❄ | 13.5 | 13.0 | 23.8 | 15.1 | 14.8 | 27.8 |
| Meta CLIP 2 | 🔥 | 15.6 | 15.2 | 27.8 | 18.3 | 17.8 | 32.8 |
| Qwen3-VL-Embedding | ❄ | 17.3 | 16.7 | 30.0 | 18.8 | 18.3 | 31.8 |
| Qwen3-VL-Embedding | 🔥 | 17.9 | 17.2 | 31.2 | 19.2 | 18.8 | 32.9 |
| Qwen3-VL-Embedding + Qwen3-VL-Reranker | 🔥 | 26.8 | 25.9 | 36.3 | 26.6 | 26.0 | 36.5 |
| UrbanLoc (Ours) | 🔥 | 34.2 | 32.9 | 48.1 | 36.2 | 35.4 | 51.9 |
❄ = zero-shot, 🔥 = fine-tuned. UrbanLoc achieved L@50 of 34.2% (New York) and 36.2% (Tokyo), outperforming all baselines on all metrics.
Qualitative Results
Success and failure cases of UrbanLoc compared with the strongest baseline (Qwen3-VL-Embedding + Qwen3-VL-Reranker).
Success Cases
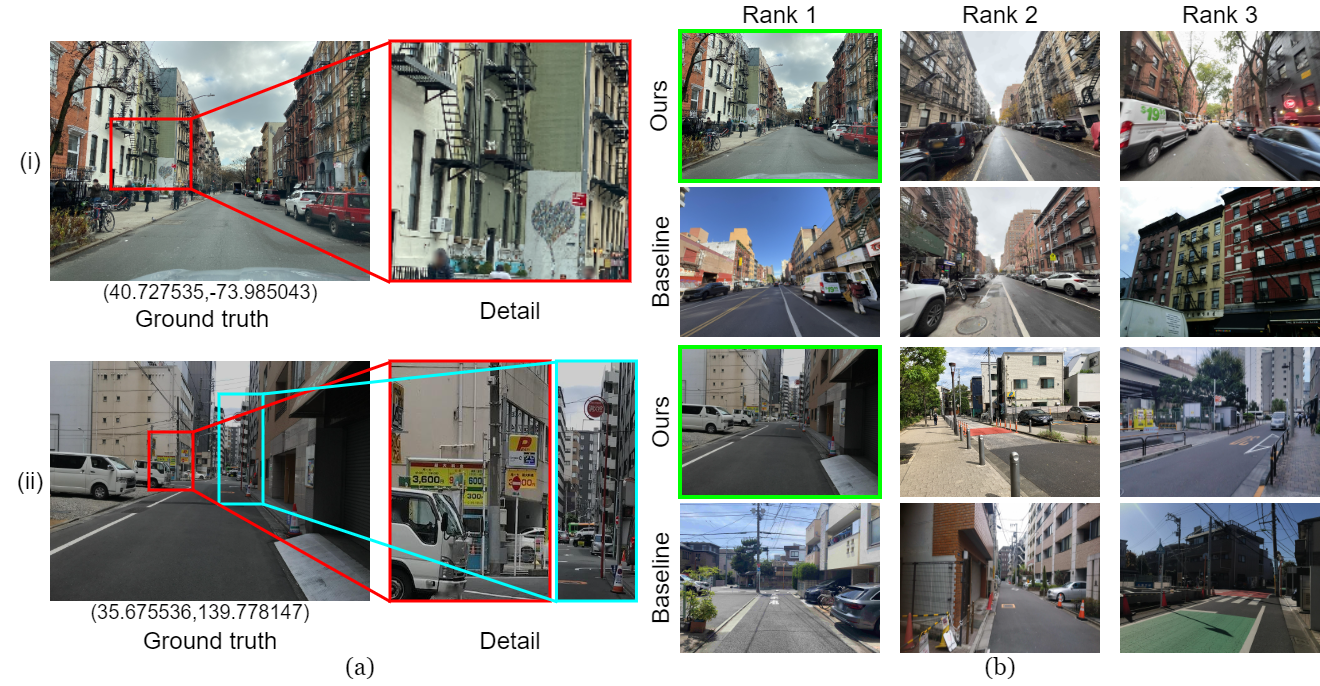
Qualitative results of UrbanLoc and a baseline method (Qwen3-VL-Embedding + Qwen3-VL-Reranker). Green frames indicate the ground-truth location images. (i) New York: "I am on a street with many brick buildings that have external stairs, and I can see a white sign with a black heart on the external wall to my front left." UrbanLoc correctly ranked the target at rank 1; the baseline ranked it at rank 104 (1.6 km error). (ii) Tokyo: "There is a parking lot on the left with a yellow sign saying max 3,600 yen, and a red sign for a fire hydrant on the right." UrbanLoc ranked the target at rank 1 by leveraging the "3,600 yen" text on the sign; the baseline ranked it at rank 85 (11.9 km error).
Failure Case

Representative failure case. Description — "I am beside a brown building, and across from it I can see a building that is white on the first floor and beige on the second floor and above." UrbanLoc ranked the target at rank 240 (56.7 km error); the baseline ranked it at rank 518 (58.0 km error). This failure stems from difficulty in capturing fine-grained combinations of visual attributes — each of the top-3 predicted locations contained some of the color cues (brown, white, or beige), but none matched the specific combination and arrangement of all three.
Ablation Study
Each component of UrbanLoc contributes to overall performance. LH = Location Head, CoT NR = CoT Narrative Representation, AS = Area Summary, STN = Scene Text Normalization, OCRR = object coverage reranking.
| Model | New York | Tokyo | ||||
|---|---|---|---|---|---|---|
| L@50 [%] ↑ | R@1 [%] ↑ | R@5 [%] ↑ | L@50 [%] ↑ | R@1 [%] ↑ | R@5 [%] ↑ | |
| (i) UrbanLoc (full) | 34.2 | 32.9 | 48.1 | 36.2 | 35.4 | 51.9 |
| (ii) w/o LH | 27.9 | 26.7 | 41.7 | 30.1 | 29.4 | 45.5 |
| (iii) w/o CoT NR | 27.9 | 26.7 | 41.3 | 28.7 | 28.0 | 43.3 |
| (iv) w/o AS | 28.0 | 26.8 | 41.6 | 29.4 | 28.7 | 44.6 |
| (v) w/o STN | 27.9 | 26.9 | 42.1 | 29.8 | 29.2 | 45.1 |
| (vi) w/o object coverage reranking | 23.9 | 22.9 | 39.5 | 25.0 | 24.3 | 43.1 |
Removing object coverage reranking causes the largest performance drop, highlighting the importance of object-level agreement. All other components also contribute meaningfully to localization accuracy.
UrbanLoc-Text Benchmark
We constructed the UrbanLoc-Text benchmark for language-guided user localization using geotagged street-view images collected via Mapillary. Test-set descriptions were collected from human annotators (151 annotators), while training/validation descriptions were generated using Qwen3-VL given street-view images and OCR-detected text. The benchmark is geographically split so that every pair of locations from different splits is separated by at least 20 m.
| Train / Val | Test | |||
|---|---|---|---|---|
| New York | Tokyo | New York | Tokyo | |
| Descriptions | 12,298 | 14,790 | 3,235 | 3,673 |
| Locations | 6,149 | 7,395 | 647 | 763 |
| Images | 6,149 | 7,395 | 647 | 763 |
| Vocabulary size | 10,254 | 11,323 | 3,874 | 4,649 |
| Word count | 515,234 | 637,535 | 88,969 | 101,514 |
| Avg. description length (words) | 41.90 | 43.11 | 27.50 | 27.64 |
| Annotators | — | 151 | ||
Error Analysis
We analyzed 100 failure cases (50 per subset) with the largest great-circle distance errors. Five major failure modes were identified.
error
Fails to capture compositional relationships among multiple concepts, including object co-occurrence and attribute–object binding.
error
Fails to correctly understand spatial relationships among multiple objects, such as relative positions or ordering.
error
Fails to properly interpret or utilize scene text information (e.g., signage text) in the candidate image.
description
Multiple candidate locations could match the given description, making it unclear which location is intended.
error
The OCR system fails to detect scene text in the candidate image, preventing text-based cues from being leveraged.
Compositionality errors are the primary bottleneck (43%). A potential direction is to incorporate an $\ell_1$-product metric over separate embedding factors, which captures cross-family composition in a Boolean-algebra-like manner.
BibTeX
Coming soon.